Simply typed lambda calculus
The simply typed lambda calculus (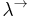 ), a form of type theory, is a typed interpretation of the lambda calculus with only one type constructor:
), a form of type theory, is a typed interpretation of the lambda calculus with only one type constructor: 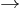 that builds function types. It is the canonical and simplest example of a typed lambda calculus. The simply typed lambda calculus was originally introduced by Alonzo Church in 1940 as an attempt to avoid paradoxical uses of the untyped lambda calculus, and it exhibits many desirable and interesting properties.
that builds function types. It is the canonical and simplest example of a typed lambda calculus. The simply typed lambda calculus was originally introduced by Alonzo Church in 1940 as an attempt to avoid paradoxical uses of the untyped lambda calculus, and it exhibits many desirable and interesting properties.
The term simple type is also used to refer to extensions of the simply typed lambda calculus such as products, coproducts or natural numbers (System T) or even full recursion (like PCF). In contrast, systems which introduce polymorphic types (like System F) or dependent types (like the Logical Framework) are not considered simply typed. The former are still considered simple because the Church encodings of such structures can be done using only and suitable type variables, while polymorphism and dependency cannot.
Contents |
Syntax
To define the types, we begin by fixing a set of base types, 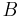 . These are sometimes called atomic types or type constants. With this fixed, the syntax of types is:
. These are sometimes called atomic types or type constants. With this fixed, the syntax of types is:
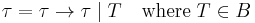 .
.
In this article, we use 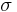 and
and 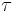 to range over types. Informally, the function type
to range over types. Informally, the function type 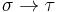 refers to the set of functions that, given an input of type , produce an output of type . By convention, associates to the right: we read
refers to the set of functions that, given an input of type , produce an output of type . By convention, associates to the right: we read 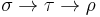 as
as 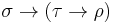 .
.
We also fix a set of term constants for the base types. For example, we might assume a base type nat, and the term constants could be the natural numbers. In the original presentation, Church used only two base types: 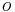 for "the type of propositions" and
for "the type of propositions" and 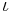 for "the type of individuals". The type has no term constants, whereas has one term constant. Frequently the calculus with only one base type, usually , is considered.
for "the type of individuals". The type has no term constants, whereas has one term constant. Frequently the calculus with only one base type, usually , is considered.
The syntax of the simply typed lambda calculus is essentially that of the lambda calculus itself. The term syntax used in this article is as follows:
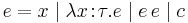
where 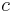 is a term constant.
is a term constant.
That is, variable reference, abstractions, application, and constant. A variable reference  is bound if it is inside of an abstraction binding . A term is closed if there are no unbound variables.
is bound if it is inside of an abstraction binding . A term is closed if there are no unbound variables.
Compare this to the syntax of untyped lambda calculus:
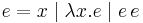
We see that in typed lambda calculus every function (abstraction) must specify the type of its argument.
Typing rules
To define the set of well typed lambda terms of a given type, we will define a typing relation between terms and types. First, we introduce typing contexts 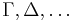 , which are sets of typing assumptions. A typing assumption has the form
, which are sets of typing assumptions. A typing assumption has the form  , meaning has type .
, meaning has type .
The typing relation 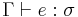 indicates that
indicates that 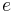 is a term of type in context
is a term of type in context 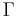 . It is therefore said that " is well-typed (at )". Instances of the typing relation are called typing judgments. The validity of a typing judgment is shown by providing a typing derivation, constructed using the following typing rules (wherein the premises above the line allow us to derive the conclusion below the line):
. It is therefore said that " is well-typed (at )". Instances of the typing relation are called typing judgments. The validity of a typing judgment is shown by providing a typing derivation, constructed using the following typing rules (wherein the premises above the line allow us to derive the conclusion below the line):
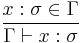 (1) (1) 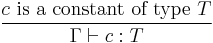 (2) (2) |
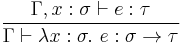 (3) (3) 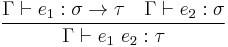 (4) (4) |
In other words,
- If has type in the context, we know that has type .
- Term constants have the appropriate base types.
- If, in a certain context with having type , has type , then, in the same context without ,
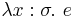 has type .
has type . - If, in a certain context,
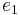 has type , and
has type , and 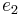 has type , then
has type , then 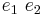 has type .
has type .
Examples of closed terms, i.e. terms typable in the empty context, are:
- For every type , a term
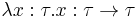 (the I-combinator/identity function),
(the I-combinator/identity function), - For types
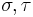 , a term
, a term 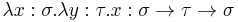 (the K-combinator), and
(the K-combinator), and - For types
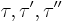 , a term
, a term 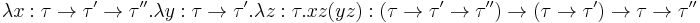 (the S-combinator).
(the S-combinator).
These are the typed lambda calculus representations of the basic combinators of combinatory logic.
Each type is assigned an order, a number 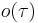 . For base types,
. For base types, 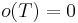 ; for function types,
; for function types, 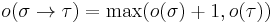 . That is, the order of a type measures the depth of the most left-nested arrow. Hence:
. That is, the order of a type measures the depth of the most left-nested arrow. Hence:
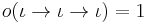
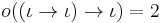
Semantics
Intrinsic vs. extrinsic interpretations
Broadly speaking, there are two different ways of assigning meaning to the simply typed lambda calculus, as to typed languages more generally, sometimes called intrinsic vs. extrinsic, or Church-style vs. Curry-style.[1] An intrinsic/Church-style semantics only assigns meaning to well-typed terms, or more precisely, assigns meaning directly to typing derivations. This has the effect that terms differing only by type annotations can nonetheless be assigned different meanings. For example, the identity term 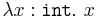 on integers and the identity term
on integers and the identity term 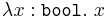 on booleans may mean different things. (The classic intended interpretations are the identity function on integers and the identity function on boolean values.) In contrast, an extrinsic/Curry-style semantics assigns meaning to terms regardless of typing, as they would be interpreted in an untyped language. In this view, and mean the same thing (i.e., the same thing as
on booleans may mean different things. (The classic intended interpretations are the identity function on integers and the identity function on boolean values.) In contrast, an extrinsic/Curry-style semantics assigns meaning to terms regardless of typing, as they would be interpreted in an untyped language. In this view, and mean the same thing (i.e., the same thing as 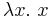 ).
).
The distinction between intrinsic and extrinsic semantics is sometimes associated with the presence or absence of annotations on lambda abstractions, but strictly speaking this usage is imprecise. It is possible to define a Curry-style semantics on annotated terms simply by ignoring the types (i.e., through type erasure), as it is possible to give a Church-style semantics on unannotated terms when the types can be deduced from context (i.e., through type inference). The essential difference between intrinsic and extrinsic approaches is just whether the typing rules are viewed as defining the language, or as a formalism for verifying properties of a more primitive underlying language. Most of the different semantic interpretations discussed below can be seen through either Church or Curry goggles.
Equational theory
The simply typed lambda calculus has the same theory of βη-equivalence as untyped lambda calculus, but subject to type restrictions. The equation ![(\lambda x:\sigma.t)\,u =_{\beta} t[x:=u]](/2012-wikipedia_en_all_nopic_01_2012/I/16864519604f87a3c0970ea845f3e587.png) holds in context whenever
holds in context whenever 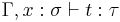 and
and 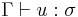 , while the equation
, while the equation 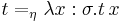 holds whenever
holds whenever 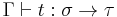 .
.
Operational semantics
Likewise, the operational semantics of simply typed lambda calculus can be fixed as for the untyped lambda calculus, using call by name, call by value, or other evaluation strategies. As for any typed language, type safety is a fundamental property of all of these evaluation strategies. Additionally, the strong normalization property described below implies that any evaluation strategy will terminate on all simply typed terms.
Categorical semantics
The simply typed lambda calculus (with 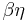 -equivalence) is the internal language of Cartesian Closed Categories (CCCs), as was first observed by Lambek.
-equivalence) is the internal language of Cartesian Closed Categories (CCCs), as was first observed by Lambek.
Proof-theoretic semantics
The simply typed lambda calculus is closely related to the implicational fragment of propositional intuitionistic logic (i.e., minimal logic) via the Curry–Howard isomorphism: terms correspond precisely to proofs in natural deduction, and inhabited types are exactly the tautologies of minimal logic.
Alternative syntaxes
The presentation given above is not the only way of defining the syntax of the simply typed lambda calculus. One alternative is to remove type annotations entirely (so that the syntax is identical to the untyped lambda calculus), while ensuring that terms are well-typed via Hindley-Milner type inference. The inference algorithm is terminating, sound, and complete: whenever a term is typable, the algorithm computes its type. More precisely, it computes the term's principal type, since often an unannotated term (such as ) may have more than one type (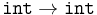 ,
, 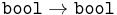 , etc., which are all instances of the principal type
, etc., which are all instances of the principal type 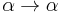 ).
).
Another alternative presentation of simply typed lambda calculus is based on bidirectional type checking, which requires more type annotations than Hindley-Milner inference but is easier to describe. The type system is divided into two judgments, representing both checking and synthesis, written 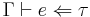 and
and 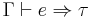 respectively. Operationally, the three components , , and are all inputs to the checking judgment , whereas the synthesis judgment only takes and as inputs, producing the type as output. These judgments are derived via the following rules:
respectively. Operationally, the three components , , and are all inputs to the checking judgment , whereas the synthesis judgment only takes and as inputs, producing the type as output. These judgments are derived via the following rules:
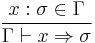 [1] [1] 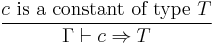 [2] [2] |
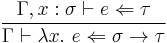 [3] [3] 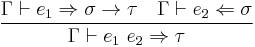 [4] [4] |
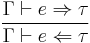 [5] [5] 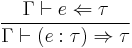 [6] [6] |
Observe that rules [1]–[4] are nearly identical to rules (1)–(4) above, except for the careful choice of checking or synthesis judgments. These choices can be explained like so:
- If is in the context, we can synthesize type for .
- The types of term constants are fixed and can be synthesized.
- To check that
 has type in some context, we extend the context with and check that has type .
has type in some context, we extend the context with and check that has type . - If synthesizes type (in some context), and checks against type (in the same context), then synthesizes type .
Observe that the rules for synthesis are read top-to-bottom, whereas the rules for checking are read bottom-to-top. Note in particular that we do not need any annotation on the lambda abstraction in rule [3], because the type of the bound variable can be deduced from the type at which we check the function. Finally, we explain rules [5] and [6] as follows:
- To check that has type , it suffices to synthesize type .
- If checks against type , then the explicitly annotated term
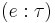 synthesizes .
synthesizes .
Because of these last two rules coercing between synthesis and checking, it is easy to see that any well-typed but unannotated term can be checked in the bidirectional system, so long as we insert "enough" type annotations. And in fact, annotations are needed only at β-redexes.
General observations
Given the standard semantics, the simply typed lambda calculus is strongly normalizing: that is, well-typed terms always reduce to a value, i.e., a 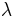 abstraction. This is because recursion is not allowed by the typing rules: it is impossible to find types for fixed-point combinators and the looping term
abstraction. This is because recursion is not allowed by the typing rules: it is impossible to find types for fixed-point combinators and the looping term 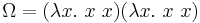 . Recursion can be added to the language by either having a special operator
. Recursion can be added to the language by either having a special operator 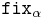 of type
of type 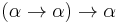 or adding general recursive types, though both eliminate strong normalization.
or adding general recursive types, though both eliminate strong normalization.
Since it is strongly normalizing, it is decidable whether or not a simply typed lambda calculus program halts: it does! We can therefore conclude that the language is not Turing complete.
Important results
- Tait showed in 1967 that
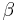 -reduction is strongly normalizing. As a corollary -equivalence is decidable. Statman showed in 1977 that the normalisation problem is not elementary recursive. A purely semantic normalisation proof (see normalisation by evaluation) was given by Berger and Schwichtenberg in 1991.
-reduction is strongly normalizing. As a corollary -equivalence is decidable. Statman showed in 1977 that the normalisation problem is not elementary recursive. A purely semantic normalisation proof (see normalisation by evaluation) was given by Berger and Schwichtenberg in 1991. - The unification problem for -equivalence is undecidable. Huet showed in 1973 that 3rd order unification is undecidable and this was improved upon by Baxter in 1978 then by Goldfarb in 1981 by showing that 2nd order unification is already undecidable. Whether higher order matching (unification where only one term contains existential variables) is decidable is still open. [2006: Colin Stirling, Edinburgh, has published a proof-sketch in which he claims that the problem is decidable; however, the complete version of the proof is still unpublished]
- We can encode natural numbers by terms of the type
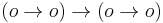 (Church numerals). Schwichtenberg showed in 1976 that in exactly the extended polynomials are representable as functions over Church numerals; these are roughly the polynomials closed up under a conditional operator.
(Church numerals). Schwichtenberg showed in 1976 that in exactly the extended polynomials are representable as functions over Church numerals; these are roughly the polynomials closed up under a conditional operator. - A full model of is given by interpreting base types as sets and function types by the set-theoretic function space. Friedman showed in 1975 that this interpretation is complete for -equivalence, if the base types are interpreted by infinite sets. Statman showed in 1983 that -equivalence is the maximal equivalence which is typically ambiguous, i.e. closed under type substitutions (Statman's Typical Ambiguity Theorem). A corollary of this is that the finite model property holds, i.e. finite sets are sufficient to distinguish terms which are not identified by -equivalence.
- Plotkin introduced logical relations in 1973 to characterize the elements of a model which are definable by lambda terms. In 1993 Jung and Tiuryn showed that a general form of logical relation (Kripke logical relations with varying arity) exactly characterizes lambda definability. Plotkin and Statman conjectured that it is decidable whether a given element of a model generated from finite sets is definable by a lambda term (Plotkin-Statman-conjecture). The conjecture was shown to be false by Loader in 1993.
Notes
- ^ Reynolds, John (1998). Theories of Programming Languages. Cambridge, England: Cambridge University Press.
References
- A. Church: A Formulation of the Simple Theory of Types, JSL 5, 1940
- W.W.Tait: Intensional Interpretations of Functionals of Finite Type I, JSL 32(2), 1967
- G.D. Plotkin: Lambda-definability and logical relations, Technical report, 1973
- G.P. Huet: The Undecidability of Unification in Third Order Logic Information and Control 22(3): 257-267 (1973)
- H. Friedman: Equality between functionals. LogicColl. '73, pages 22-37, LNM 453, 1975.
- H. Schwichtenberg: Functions definable in the simply-typed lambda calculus, Arch. Math Logik 17 (1976) 113-114.
- R. Statman: The Typed lambda-Calculus Is not Elementary Recursive FOCS 1977: 90-94
- W. D. Goldfarb: The undecidability of the 2nd order unification problem, TCS (1981), no. 13, 225- 230.
- R. Statman. -definable functionals and conversion. Arch. Math. Logik, 23:21--26, 1983.
- J. Lambek: Cartesian Closed Categories and Typed Lambda-calculi. Combinators and Functional Programming Languages 1985: 136-175
- U. Berger, H. Schwichtenberg: An Inverse of the Evaluation Functional for Typed lambda-calculus LICS 1991: 203-211
- Jung, A.,Tiuryn, J.:A New Characterization of Lambda Definability, TLCA 1993
- R. Loader: The Undecidability of λ-definability, appeared in the Church Festschrift, 2001
- H. Barendregt, Lambda Calculi with Types, Handbook of Logic in Computer Science, Volume II, Oxford University Press, 1993. ISBN 0-19-853761-1.
- L. Baxter: The undecidability of the third order dyadic unification problem, Information and Control 38(2), 170-178 (1978)
See also
- Article Church's Type Theory in the Stanford Encyclopedia of Philosophy.
- Hindley-Milner type inference algorithm
External links
- Loader, Ralph (February 1998). "Notes on Simply Typed Lambda Calculus". http://www.lfcs.inf.ed.ac.uk/reports/98/ECS-LFCS-98-381/.